Last week in the lead up to the Council’s Emergency budget debate we learnt the government had agreed to nearly $200 million of funding from their ‘shovel ready’ project fund in response to COVID-19. Of this, $98 million was for projects in the council’s budget, and there was another $98 million for other projects not in the budget. In both cases there was no information as to what projects the money would be going to but that changed on Saturday with the government finally announcing what projects were being funded.
The $98 million towards the council projects is the least interesting aspect of the announcement. This is going to be used for two projects already under construction and the funding really just enables council finances to be freed up for other things. The two projects are the Puhinui Interchange and Stage One of the Ferry Basin Redevelopment.
It’s the other two projects that are more interesting. These are:
Northwest Bus improvements
Auckland Transport is to be given $50 million from the infrastructure fund and is able to get another $50 million from Waka Kotahi to put in place the first stages of a rapid transit route to the Northwest.
The Northwestern Bus Improvements involves a range of short-term works which includes new bus interchanges at Te Atatū Rd, Lincoln Rd and Westgate, local bus stop improvements, and bus priority at motorway interchanges and along motorway shoulders.
They also said:
The Northwestern Bus Improvements could mean up to 35 minutes saved on a bus trip from Westgate into the city.
This is the staged plan AT came up with that we highlighted back in January.
As highlighted above, stage 1 is to build a few busway stations and add to the existing bus shoulders/priority along the route. It was expected to cost $20-40 million but understand more detailed work has now been done which has increased that a bit.

In many ways this is the same approach that was taken with the Northern Busway which started with just the Albany and Constellation stations and buses running on motorway shoulders and then shifting to the dedicated busway once it was built (and soon extended)
This would also enable AT to rework the bus network out west to feed the proposed bus stations. In my post about Auckland’s busiest bus routes I grouped all the services that use the NW motorway, which came out as the 13th busiest route. With these changes it would quickly move up the list.
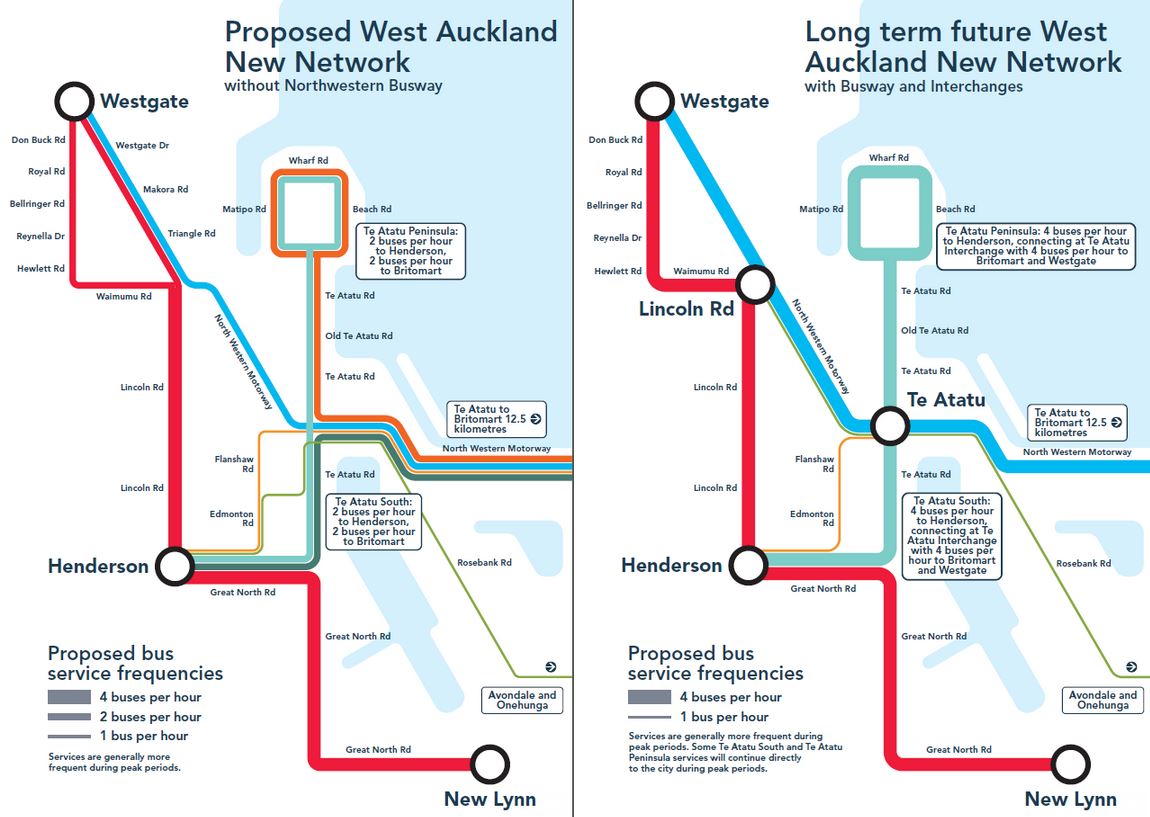
From when Auckland Transport consulted on the new network for West Auckland
However, the press release also talks about a potential station at Lincoln Rd as well as local bus stops and so combined with the larger $100m budget it seems we could effectively be doing step 1.5. This would make the improvements even more beneficial and help any local bus changes above work better.

It’s good to finally see rapid transit progressing on the Northwest. It is expected that a staged busway such as this would increase the throughput from all modes of the NW motorway at Waterview from 11,000 per hour to 16,000 per hour. So basically a 50% increase in capacity for just two lanes. It’s crazy that it was never included in the widening that’s only just been completed.
We should also be taking approach to get the Upper Harbour RTN implemented.
Te Whau Pathway
The other project announced was $37 million towards the Te Whau pathway – the planned path that will meander along the western side of the Whau River and when finished will link both harbours with a 15km path that links up 33 reserves, esplanade reserves, sports parks and roads.

It’s not the full pathway that’s being funded though, but it will be a decent chunk of it.
“The Te Whau Pathway will be extended through New Lynn, from Olympic Park to Ken Maunder Park, and through Te Atatū South, from Laurieston Park to the North Western Cycleway. This will give these communities an easy and safe way to get around.
These two sections are highlighted in purple below. I imagine the Northern one could be quite popular for getting locals to the NW cycleway while the Southern one will link into the currently under construction New Lynn to Avondale path.
 It was also announced that this project is part of a wider $220 million nationwide cycleways package – more details of which will be announced later but presumably will be outside of Auckland.
It was also announced that this project is part of a wider $220 million nationwide cycleways package – more details of which will be announced later but presumably will be outside of Auckland.
Both projects still need design and consenting work but are expected to start construction next year.

 Processing...
Processing...
“Both projects still need design and consenting work but are expected to start construction next year”.
Generous definition of shovel ready then.
Highlights how long overdue these are
More spin from the CoL.
Highlights the fact that they don’t have a plan to get the economy growing.
Vance, really? Two of the four are so shovel ready they’re actually underway now, but covid affected their funding stream. So better than shovel ready; shovel current. The other two mean immediate work for planners, designers, and engineers, followed by foot soldiers next year.
These are real actual useful and well scaled programmes not unreal and unfundable empty promises from lying politicians and foolish retired rail buffs.
The economy is going to need some growing next year when the global impact of Covid really sinks in.
The hilarious thing is that probably no-one remembers what failed National Party buzzphrase “CoL” is supposed to stand for
There aren’t a lot of unfunded projects with detailed design and resource consent out there. Because why would you spend the money on detailed design and consenting for a project that might not happen?
The most ‘shovel ready’ projects are things that don’t require consenting at all, like repairing or replacing aging infrastructure. Hence why the government is funding some 3 waters upgrades. I expect we’ll see funding for catching up on deferred maintenance of school buildings and hospitals too.
“Both projects still need design and consenting work but are expected to start construction next year”
Or in other words: NOT “shovel ready”.
Give how long a NW busway to Massey has been needed & talked about: That is in itself a disgrace.
Te Whau pathway has so many benefits; environmental, cultural, educational etc but in terms of transport this will give a huge number of West Aucklanders a short ( just over 3kms) ride to good PT at Te Atatu with the busway and New Lynn with the train.
Or 2km if they straighten it.
+1 to you both.
These are the kinds of projects I like – they are of appropriate scale, they can be started soon (within months), and they will both provide better alternatives to private vehicle usage. This equals better safety and reduced pollution and CO2 emissions. Let’s see a lot more of this!
+1
+1000
I suppose the busway or bus priority from Manukau Puhinui then the Airport will be available for Intercity, tourist coaches and shuttles to use as well. Presumably there will be an entrance point to 20 B where it crosses highway 20.
They’re going to be transit lanes so will be easy to access for any bus.
Seems a shame that they are transit lanes, but I really hope they’re T3 and not T2 lanes.
What is the Te Whau pathway constructed of ? . Will it be timber [ like the one in Orakei ] , or Concrete .
I was of the understanding that some part of the Auckland to Manukau Project (even AtoB)/ Puhinui Interchange had been deferred because of Auckland Council budget constraint. Does this additional funding allow this to continue or will then money planned to be spent by AT as part of the the revised work programme get spent elsewhere?
Yes very exciting news about Te Whau, I hope Glendene and Kelston sections get funding soon too, as having the full path really opens up New Lynn/Avondale to the rest of the NW suburbs, without the circuitous detour via Waterview.
The next big thing for the west would really be extending the rail corridor cycleway from New Lynn to Swanson.
Also exciting to hear they are finally progressing with the early bus measures on the NW, they were talking about the continuous treatment for a few years now but nothing. The stations are a great add – Te Atatu is probably the most exciting, as that will enable merging bus routes 132 and 133 into the 131 and making the 131 frequent route 13 (also route 134 no longer to city, and hopefully a bit more frequent). Then having the other two stations will enable having a WEX (or WX1) route run motorway to new Te Atatu, Lincoln and Westgate stations (and no more 110, as it would duplicate 14W/T).
Yes.
Good news. I can imagine the Te Atatū interchange would be very useful.
131, 133 and 134 all go through different parts of Te Atatu South to get from the motorway to Henderson, so if they are all merged into one route it will be interesting to see where.
While I’ve used the 132 many times and found it an effective quite route to get from the city/peninsula and vice versa I still prefer having the bus interchange.
Yeah so 132 and 133 would likely be removed. Existing route 131 would be made into route 13 which interfaces at the busway station (or stations for the temporary dual sided scenario). As 134 takes a route not covered by 131(13) that would be made to run the busway stations instead of city, and hopefully upgraded to connector (from local).
131 covers all of what 132 and 133 cover without the city leg. Which of course would be handled by the WX1.
At least thats my understanding of what they want to do.
Great to see this funding signed off and let’s look to what’s next after the middle bit of Te Whau is funded.
A great addition to the Te Whau pathway would be a pedestrian and cycle bridge over the Whau creek from Laurieston Park to the vicinity of the West End Rowing Club. Then a connection to Rosebank Rd and the NW Cycleway. This would significantly ease access to the Patiki Rod industrial area for western workers and shorten the route from the Mid West to the cycleway. Must be specifically NOT for cars and trucks.
Awesome idea Mr Plod. Anything to improve active modes around Rosebank would be amazing for all users of that area. It seems unlikely any quality improvements will be made to the road for active modes in the near future.
This would be nirvana for me in terms of a fast connection to/from Glen Eden village. I think sadly the idea of a crossing was mooted and turned down at consultation stage a few years back. To be honest I’ll be happy if the connection from Ken Maunder to the Avondale path is in place in the next few years. Getting tired of Great North Road through New Lynn as the only realistic (not to mention bike-legal) connection.
Another to Avondale Rd reserve would be good too.